QEMU 事件循环机制简析(二):基本组成
前言
QEMU 采用了基于事件驱动的架构,其事件循环机制基于 glib 实现,上一篇文章介绍了 glib 事件循环机制,本文将在此基础上以 8.0.0 版本的 QEMU RISC-V (qemu-system-riscv64) 为例深入分析 QEMU 事件循环机制。
概述
QEMU 的事件循环机制是其核心功能之一,用于协调虚拟机的各种异步操作。通过监听和调度各种事件源,它允许 QEMU 有效地响应外部输入、定时器事件等,从而实现高性能的虚拟化。
QEMU 的默认事件循环是位于文件 utils/main-loop.c 文件中的主循环 main-loop,我们也可以使用选项 –object iothread, id=<my_iothread_name> 自己创建事件循环。
QEMU 事件源
尽管 QEMU 的事件循环机制基于 glib 实现,但是 QEMU 没有直接使用 glib 提供的事件源,而是自定义了一个新的事件源 AioContext,主要有以下两种类型:
- 监听各种事件,例如
iohandler_ctx - 处理块设备层的异步 I/O 请求,例如默认的
qemu_aio_context或者模块自己创建的AioContext
/* include/block/aio.h: 124 */
struct AioContext {
GSource source;
/* Used by AioContext users to protect from multi-threaded access. */
QemuRecMutex lock;
/*
* Keep track of readers and writers of the block layer graph.
* This is essential to avoid performing additions and removal
* of nodes and edges from block graph while some
* other thread is traversing it.
*/
BdrvGraphRWlock *bdrv_graph;
/* The list of registered AIO handlers. Protected by ctx->list_lock. */
AioHandlerList aio_handlers;
/* The list of AIO handlers to be deleted. Protected by ctx->list_lock. */
AioHandlerList deleted_aio_handlers;
/* Used to avoid unnecessary event_notifier_set calls in aio_notify;
* only written from the AioContext home thread, or under the BQL in
* the case of the main AioContext. However, it is read from any
* thread so it is still accessed with atomic primitives.
*
* If this field is 0, everything (file descriptors, bottom halves,
* timers) will be re-evaluated before the next blocking poll() or
* io_uring wait; therefore, the event_notifier_set call can be
* skipped. If it is non-zero, you may need to wake up a concurrent
* aio_poll or the glib main event loop, making event_notifier_set
* necessary.
*
* Bit 0 is reserved for GSource usage of the AioContext, and is 1
* between a call to aio_ctx_prepare and the next call to aio_ctx_check.
* Bits 1-31 simply count the number of active calls to aio_poll
* that are in the prepare or poll phase.
*
* The GSource and aio_poll must use a different mechanism because
* there is no certainty that a call to GSource's prepare callback
* (via g_main_context_prepare) is indeed followed by check and
* dispatch. It's not clear whether this would be a bug, but let's
* play safe and allow it---it will just cause extra calls to
* event_notifier_set until the next call to dispatch.
*
* Instead, the aio_poll calls include both the prepare and the
* dispatch phase, hence a simple counter is enough for them.
*/
uint32_t notify_me;
/* A lock to protect between QEMUBH and AioHandler adders and deleter,
* and to ensure that no callbacks are removed while we're walking and
* dispatching them.
*/
QemuLockCnt list_lock;
/* Bottom Halves pending aio_bh_poll() processing */
BHList bh_list;
/* Chained BH list slices for each nested aio_bh_poll() call */
QSIMPLEQ_HEAD(, BHListSlice) bh_slice_list;
/* Used by aio_notify.
*
* "notified" is used to avoid expensive event_notifier_test_and_clear
* calls. When it is clear, the EventNotifier is clear, or one thread
* is going to clear "notified" before processing more events. False
* positives are possible, i.e. "notified" could be set even though the
* EventNotifier is clear.
*
* Note that event_notifier_set *cannot* be optimized the same way. For
* more information on the problem that would result, see "#ifdef BUG2"
* in the docs/aio_notify_accept.promela formal model.
*/
bool notified;
EventNotifier notifier;
QSLIST_HEAD(, Coroutine) scheduled_coroutines;
QEMUBH *co_schedule_bh;
int thread_pool_min;
int thread_pool_max;
/* Thread pool for performing work and receiving completion callbacks.
* Has its own locking.
*/
struct ThreadPool *thread_pool;
#ifdef CONFIG_LINUX_AIO
/*
* State for native Linux AIO. Uses aio_context_acquire/release for
* locking.
*/
struct LinuxAioState *linux_aio;
#endif
#ifdef CONFIG_LINUX_IO_URING
/*
* State for Linux io_uring. Uses aio_context_acquire/release for
* locking.
*/
struct LuringState *linux_io_uring;
/* State for file descriptor monitoring using Linux io_uring */
struct io_uring fdmon_io_uring;
AioHandlerSList submit_list;
#endif
/* TimerLists for calling timers - one per clock type. Has its own
* locking.
*/
QEMUTimerListGroup tlg;
int external_disable_cnt;
/* Number of AioHandlers without .io_poll() */
int poll_disable_cnt;
/* Polling mode parameters */
int64_t poll_ns; /* current polling time in nanoseconds */
int64_t poll_max_ns; /* maximum polling time in nanoseconds */
int64_t poll_grow; /* polling time growth factor */
int64_t poll_shrink; /* polling time shrink factor */
/* AIO engine parameters */
int64_t aio_max_batch; /* maximum number of requests in a batch */
/*
* List of handlers participating in userspace polling. Protected by
* ctx->list_lock. Iterated and modified mostly by the event loop thread
* from aio_poll() with ctx->list_lock incremented. aio_set_fd_handler()
* only touches the list to delete nodes if ctx->list_lock's count is zero.
*/
AioHandlerList poll_aio_handlers;
/* Are we in polling mode or monitoring file descriptors? */
bool poll_started;
/* epoll(7) state used when built with CONFIG_EPOLL */
int epollfd;
const FDMonOps *fdmon_ops;
};上述结构体较为复杂,下面主要分析几个较为关键的成员变量的含义与作用:
- GSource source: glib 事件源,每一个 glib 自定义事件源的第一个成员必须是
GSource结构的成员 - QemuRecMutex lock: 用于保护
AioContext的递归互斥锁,防止多线程访问 - AioHandlerList aio_handlers: 一个链表头,其链表中的数据类型为
AioHandler,所有加入到AioContext事件源的文件 fd 的事件处理函数都挂载到该链表上 - uint32_t notify_me:用于避免在
aio_notify中进行不必要的event_notifier_set调用 - bool notified:
notify_me和notified都与aio_notify相关,主要用于在块设备层的 I/O 同步时处理 QEMU 下半部 (Bottom Halvs,BH) - BHList bh_list: QEMU 下半部链表,用来连接挂到该事件源的下半部,QEMU 的 BH 默认挂载到
qemu_aio_context下 - EventNotifier notifier: 事件通知对象,在块设备进行同步且需要调用 BH 的时候需要用到该成员
- QEMUTimerListGroup tlg: 管理挂到该事件源的定时器
AioContext 拓展了 glib 中事件源的功能,不但支持 fd 的事件处理,还模拟内核中的下半部机制,实现了 QEMU 中的下半部以及定时器的管理。AioContext 可以通过调用 aio_context_new 函数进行创建并初始化:
/* util/async.c: 542 */
AioContext *aio_context_new(Error **errp)
{
int ret;
AioContext *ctx;
ctx = (AioContext *) g_source_new(&aio_source_funcs, sizeof(AioContext));
QSLIST_INIT(&ctx->bh_list);
QSIMPLEQ_INIT(&ctx->bh_slice_list);
aio_context_setup(ctx);
ret = event_notifier_init(&ctx->notifier, false);
if (ret < 0) {
error_setg_errno(errp, -ret, "Failed to initialize event notifier");
goto fail;
}
g_source_set_can_recurse(&ctx->source, true);
qemu_lockcnt_init(&ctx->list_lock);
ctx->co_schedule_bh = aio_bh_new(ctx, co_schedule_bh_cb, ctx);
QSLIST_INIT(&ctx->scheduled_coroutines);
aio_set_event_notifier(ctx, &ctx->notifier,
false,
aio_context_notifier_cb,
aio_context_notifier_poll,
aio_context_notifier_poll_ready);
#ifdef CONFIG_LINUX_AIO
ctx->linux_aio = NULL;
#endif
#ifdef CONFIG_LINUX_IO_URING
ctx->linux_io_uring = NULL;
#endif
ctx->thread_pool = NULL;
qemu_rec_mutex_init(&ctx->lock);
timerlistgroup_init(&ctx->tlg, aio_timerlist_notify, ctx);
ctx->poll_ns = 0;
ctx->poll_max_ns = 0;
ctx->poll_grow = 0;
ctx->poll_shrink = 0;
ctx->aio_max_batch = 0;
ctx->thread_pool_min = 0;
ctx->thread_pool_max = THREAD_POOL_MAX_THREADS_DEFAULT;
register_aiocontext(ctx);
return ctx;
fail:
g_source_destroy(&ctx->source);
return NULL;
}aio_context_new 函数返回一个指向新创建的 AioContext 的指针,并接受一个 Error 指针的指针,用于报告初始化过程中出现的错误。该函数首先调用 g_source_new 等函数完成 AioContext 的创建、设置以及 QEMU 下半部列表的初始化,接着初始化事件通知器及其回调函数、初始化锁并设置协程调度,然后完成线程池、计时器列表、轮询参数等其他内容的初始化工作,最后注册新创建的 AioContext。
在 AioContext 的创建函数中,aio_set_event_notifer 函数调用了 aio_set_fd_handler 函数,后者用于添加或者删除 AioContext 事件源中的 fd,如果是添加则会设置 fd 对应的读写函数。添加事件源中 fd 监听处理的具体过程如下:
/* util/aio-posix.c: 100 */
void aio_set_fd_handler(AioContext *ctx,
int fd,
bool is_external,
IOHandler *io_read,
IOHandler *io_write,
AioPollFn *io_poll,
IOHandler *io_poll_ready,
void *opaque)
{
AioHandler *node;
AioHandler *new_node = NULL;
bool is_new = false;
bool deleted = false;
int poll_disable_change;
if (io_poll && !io_poll_ready) {
io_poll = NULL; /* polling only makes sense if there is a handler */
}
qemu_lockcnt_lock(&ctx->list_lock);
node = find_aio_handler(ctx, fd);
/* Are we deleting the fd handler? */
if (!io_read && !io_write && !io_poll) {
if (node == NULL) {
qemu_lockcnt_unlock(&ctx->list_lock);
return;
}
/* Clean events in order to unregister fd from the ctx epoll. */
node->pfd.events = 0;
poll_disable_change = -!node->io_poll;
} else {
poll_disable_change = !io_poll - (node && !node->io_poll);
if (node == NULL) {
is_new = true;
}
/* Alloc and insert if it's not already there */
new_node = g_new0(AioHandler, 1);
/* Update handler with latest information */
new_node->io_read = io_read;
new_node->io_write = io_write;
new_node->io_poll = io_poll;
new_node->io_poll_ready = io_poll_ready;
new_node->opaque = opaque;
new_node->is_external = is_external;
if (is_new) {
new_node->pfd.fd = fd;
} else {
new_node->pfd = node->pfd;
}
g_source_add_poll(&ctx->source, &new_node->pfd);
new_node->pfd.events = (io_read ? G_IO_IN | G_IO_HUP | G_IO_ERR : 0);
new_node->pfd.events |= (io_write ? G_IO_OUT | G_IO_ERR : 0);
QLIST_INSERT_HEAD_RCU(&ctx->aio_handlers, new_node, node);
}
/* No need to order poll_disable_cnt writes against other updates;
* the counter is only used to avoid wasting time and latency on
* iterated polling when the system call will be ultimately necessary.
* Changing handlers is a rare event, and a little wasted polling until
* the aio_notify below is not an issue.
*/
qatomic_set(&ctx->poll_disable_cnt,
qatomic_read(&ctx->poll_disable_cnt) + poll_disable_change);
ctx->fdmon_ops->update(ctx, node, new_node);
if (node) {
deleted = aio_remove_fd_handler(ctx, node);
}
qemu_lockcnt_unlock(&ctx->list_lock);
aio_notify(ctx);
if (deleted) {
g_free(node);
}
}该函数接受以下 6 个参数:
- AioContext *ctx: 待添加 fd 的异步 I/O 上下文
- int fd: 待处理的文件描述符
- bool is_external: 用于块设备层,指示是否为外部事件,对于事件监听的 fd 都设置为
false - IOHandler *io_read: 读取回调函数
- IOHandler *io_write: 写入回调函数
- AioPollFn *io_poll: 轮询回调函数
- IOHandler *io_poll_ready: 轮询就绪回调函数
- void *opaque: 传递给回调函数的透明指针
aio_set_fd_handler 函数首先调用 find_aio_handler 查找当前事件源中是否已有 fd,对于新加入的情况,这里会创建一个名为 node 的 AioHandler,使用 fd 初始化 node->pfd.fd,并将其插入到 ctx->aio_handlers 链表上,调用 glib 接口函数 g_source_add_poll 将该 fd 插入到了事件源监听 fd 列表中。最后设置 node 的事件读写函数为 io_read 和 io_write,根据 io_read 和 io_write 的有无设置 node->pfd.events,即要监听的事件。在 aio_set_fd_handler 执行完成之后,新的 fd 事件就加入到了事件源的 aio_handlers 链表上了,具体如下图所示:
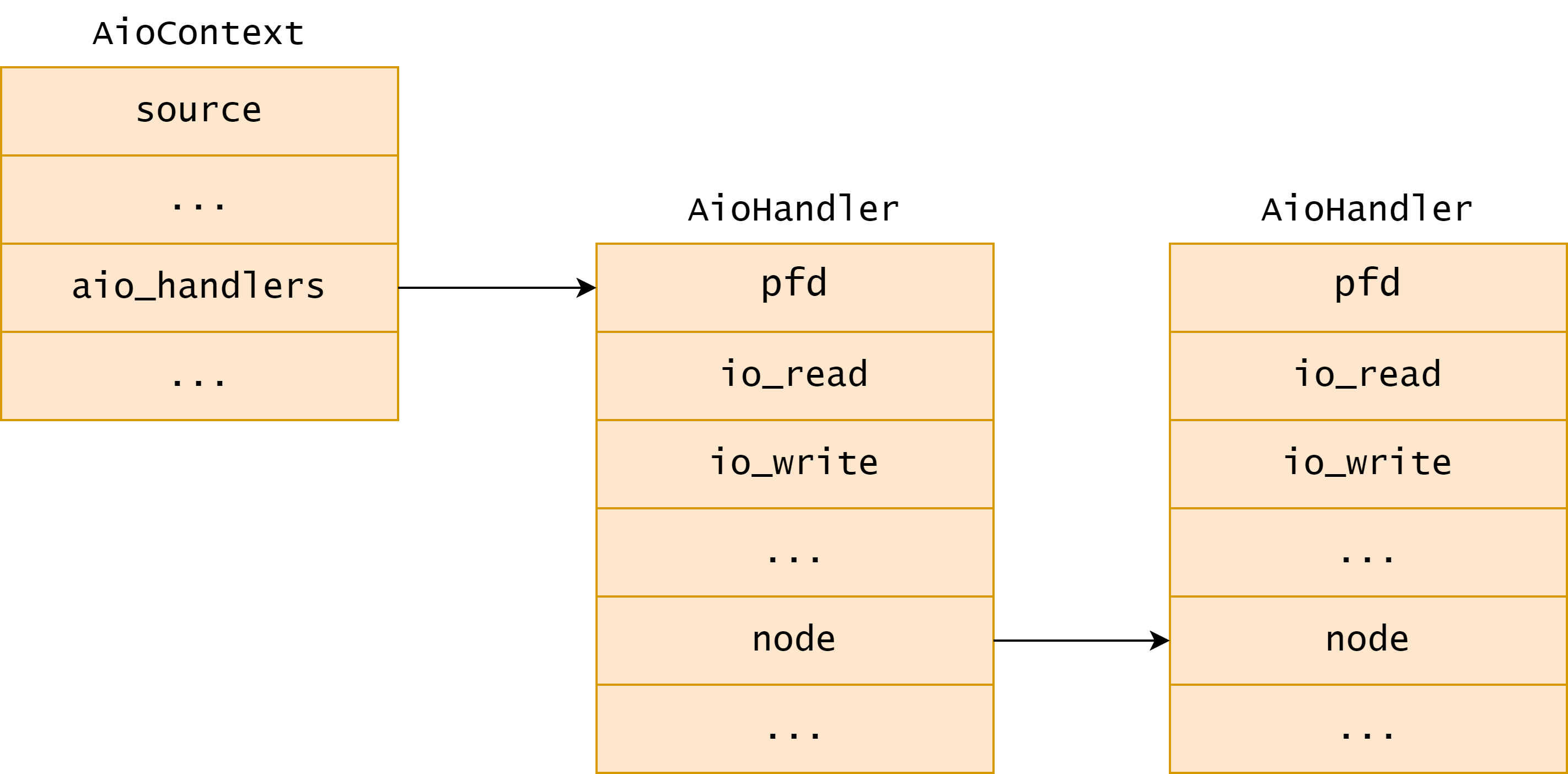
状态机回调函数
QEMU 丰富了 glib 的事件源,状态机回调函数的实现逻辑变得更加复杂,但基本框架仍然遵循 glib 规范,aio_context_new 函数中的 aio_source_funcs 是状态机回调函数的声明:
/* util/async.c: 389 */
static GSourceFuncs aio_source_funcs = {
aio_ctx_prepare,
aio_ctx_check,
aio_ctx_dispatch,
aio_ctx_finalize
};其中 aio_ctx_prepare 是状态机 prepare 阶段的回调函数,目的是准备 AioContext 进行轮询,计算超时,并检查是否有即时事件需要处理。如果有即时事件,它会返回 true,这意味着主事件循环应该立即处理这些事件而非等待。
/* util/async.c: 267 */
static gboolean
aio_ctx_prepare(GSource *source, gint *timeout)
{
AioContext *ctx = (AioContext *) source;
qatomic_set(&ctx->notify_me, qatomic_read(&ctx->notify_me) | 1);
/*
* Write ctx->notify_me before computing the timeout
* (reading bottom half flags, etc.). Pairs with
* smp_mb in aio_notify().
*/
smp_mb();
/* We assume there is no timeout already supplied */
*timeout = qemu_timeout_ns_to_ms(aio_compute_timeout(ctx));
if (aio_prepare(ctx)) {
*timeout = 0;
}
return *timeout == 0;
}aio_ctx_check 是状态机 check 阶段的回调函数,主要负责检查 AioContext 是否有待处理的事件。如果有则返回 true。该函数首先使用原子操作清除 ctx->notify_me 的最低位,这是用于跟踪是否需要通知 AioContext 的标志。接着调用 aio_notify_accept 来处理任何挂起的通知,并通过 QSLIST_FOREACH_RCU 宏遍历 ctx->bh_list 中的所有下半部,如果找到一个已调度但未删除的下半部,函数返回 true。然后,使用 QSIMPLEQ_FOREACH 和 QSLIST_FOREACH_RCU 宏遍历 ctx->bh_slice_list 中的所有下半部,如果在任何切片中找到一个已调度但未删除的下半部,函数返回 true。最后,使用 aio_pending 函数检查是否有其他挂起的事件。此外,函数还会检查 timerlistgroup_deadline_ns 的返回值是否为 0,这意味着有一个立即的定时器事件需要处理。
/* util/async.c: 291 */
static gboolean
aio_ctx_check(GSource *source)
{
AioContext *ctx = (AioContext *) source;
QEMUBH *bh;
BHListSlice *s;
/* Finish computing the timeout before clearing the flag. */
qatomic_store_release(&ctx->notify_me, qatomic_read(&ctx->notify_me) & ~1);
aio_notify_accept(ctx);
QSLIST_FOREACH_RCU(bh, &ctx->bh_list, next) {
if ((bh->flags & (BH_SCHEDULED | BH_DELETED)) == BH_SCHEDULED) {
return true;
}
}
QSIMPLEQ_FOREACH(s, &ctx->bh_slice_list, next) {
QSLIST_FOREACH_RCU(bh, &s->bh_list, next) {
if ((bh->flags & (BH_SCHEDULED | BH_DELETED)) == BH_SCHEDULED) {
return true;
}
}
}
return aio_pending(ctx) || (timerlistgroup_deadline_ns(&ctx->tlg) == 0);
}aio_ctx_dispatch 是状态机 dispatch 阶段的回调函数,整体逻辑较为简单,在确保参数 callback 不为空的情况下直接调用 aio_dispatch 函数进行处理。
/* util/async.c: 318 */
static gboolean
aio_ctx_dispatch(GSource *source,
GSourceFunc callback,
gpointer user_data)
{
AioContext *ctx = (AioContext *) source;
assert(callback == NULL);
aio_dispatch(ctx);
return true;
}aio_dispatch 函数是所有事件处理函数中最为重要的一个,主要负责事件的分派处理,具体负责:
- 下半部处理
- 处理文件 fd 列表中有事件的 fd
- 调用定时器到期的函数
aio_dispatch 函数代码对上述三个行为进行了封装:
/* util/aio-posix.c: 418 */
void aio_dispatch(AioContext *ctx)
{
qemu_lockcnt_inc(&ctx->list_lock);
aio_bh_poll(ctx);
aio_dispatch_handlers(ctx, INVALID_HANDLE_VALUE);
qemu_lockcnt_dec(&ctx->list_lock);
timerlistgroup_run_timers(&ctx->tlg);
}这里我们重点关注 aio_dispatch_handlers 函数的执行逻辑:
/* util/aio-posix.c: 406 */
static bool aio_dispatch_handlers(AioContext *ctx, HANDLE event)
{
AioHandler *node;
bool progress = false;
AioHandler *tmp;
/*
* We have to walk very carefully in case aio_set_fd_handler is
* called while we're walking.
*/
QLIST_FOREACH_SAFE_RCU(node, &ctx->aio_handlers, node, tmp) {
int revents = node->pfd.revents;
if (!node->deleted &&
(revents || event_notifier_get_handle(node->e) == event) &&
node->io_notify) {
node->pfd.revents = 0;
node->io_notify(node->e);
/* aio_notify() does not count as progress */
if (node->e != &ctx->notifier) {
progress = true;
}
}
if (!node->deleted &&
(node->io_read || node->io_write)) {
node->pfd.revents = 0;
if ((revents & G_IO_IN) && node->io_read) {
node->io_read(node->opaque);
progress = true;
}
if ((revents & G_IO_OUT) && node->io_write) {
node->io_write(node->opaque);
progress = true;
}
/* if the next select() will return an event, we have progressed */
if (event == event_notifier_get_handle(&ctx->notifier)) {
WSANETWORKEVENTS ev;
WSAEnumNetworkEvents(node->pfd.fd, event, &ev);
if (ev.lNetworkEvents) {
progress = true;
}
}
}
if (node->deleted) {
if (qemu_lockcnt_dec_if_lock(&ctx->list_lock)) {
QLIST_REMOVE(node, node);
g_free(node);
qemu_lockcnt_inc_and_unlock(&ctx->list_lock);
}
}
}
return progress;
}aio_dispatch_handlers 函数的行为主要分为 4 个步骤:
- 使用
QLIST_FOREACH_SAFE_RCU宏安全地遍历ctx->aio_handlers列表,检查监听 fd 上的事件是否发生。fd 发生的事件存在node->pfd.revents中,注册时指定需要接受的事件存放在node->pfd.events中,revents变量保存了 fd 接收到的事件。 - 处理通知,如果事件没有被删除,其事件标志被设置,且有一个通知回调函数,那么该回调函数将被调用。
- 处理读写事件,对应
G_IO_IN可读事件来说,会调用注册的 fd 的io_read回调,对G_IN_OUT可写事件来说,会调用注册的 fd 的io_write函数。 - 如果当前的 fd 已经被标记删除了,则会删除这个节点并释放锁。
aio_ctx_finalize 函数是事件源不再被引用时的回调函数,其主要目的是确保与 AioContext 关联的所有资源都被正确地清理和释放,以防止发生内存泄漏等问题。aio_ctx_finalize 函数的整体逻辑相对而言比较简单,这里不再赘述。
poll 机制
应用程序对文件描述符的读写,一般有两种方式:
- 阻塞式 IO: 如果 fd 的某个状态(比如可读,可写)没有准备就绪,进程将永远阻塞在这个 IO 上
- 非阻塞式 IO: 进程 IO 立即执行,如果 fd 没有准备就绪,直接返回错误,表示如果继续执行 IO 将阻塞。
通常来说,上述两种方式能够满足大多数应用程序对文件描述符的读写需求,但是在更复杂的场景下,比如一个不允许阻塞的进程需要读写一个可能永远阻塞进程的 fd,这时就需要使用内核提供的 poll 机制。poll 机制不直接读写 IO,而是先探测 fd 的 IO 状态是否就绪。这个探测行为可以设置超时时间:如果在超时时间到达前 IO 状态准备就绪,poll 接口立即返回,指示应用程序可以进行读写操作;如果 poll 超过了设置的超时时间,但应用需要的 IO 状态仍未完全就绪,poll 接口也会返回,同时把已经就绪的部分 IO 状态返回。这种机制使得应用程序能够根据内核返回的 poll 信息确定下一步的操作,避免应用程序被永远阻塞在某一 IO 上。
QEMU 基于 glib 事件循环的框架,定制了 glib 事件循环机制中几乎所有的接口。需要注意的是,QEMU 并没有调用 glib 的接口 g_main_loop_run 执行事件循环,而是直接调用了 glib 提供的 g_poll 函数实现 poll 的功能。g_poll 函数具有可移植性,在有 poll 接口的平台上由 poll 模拟,在没有 poll 接口的平台上由 select 模拟。当用户不想执行整个 glib 事件循环,又想实现阻塞一段时间的高级 IO,就可以通过直接调用 g_poll 实现。
QEMU 主事件循环的具体逻辑由函数 qemu_main_loop 体现:
/* softmmu/runstate.c: 720 */
int qemu_main_loop(void)
{
int status = EXIT_SUCCESS;
#ifdef CONFIG_PROFILER
int64_t ti;
#endif
while (!main_loop_should_exit(&status)) {
#ifdef CONFIG_PROFILER
ti = profile_getclock();
#endif
main_loop_wait(false);
#ifdef CONFIG_PROFILER
dev_time += profile_getclock() - ti;
#endif
}
return status;
}观察上述代码我们可以发现,QEMU 使用了一条 while 语句循环调用 main_loop_wait 函数,再通过一串函数调用链最终调用 g_poll 接口。g_poll 接口接受的参数是一个文件描述符的数组,因此它能够同时 poll 多个 fd,poll 的时候是休眠的,一旦其中一个 fd 准备好,poll 就会被唤醒,同时 GPollFD.revent 会被内核设置,以表明 fd 的状态。QEMU 对 g_poll 接口的封装实现除了以纳秒为单位计算超时之外,其他方面均与 glib 的 g_poll 接口保持一致:
/* util/qemu-timer.c: 335 */
int qemu_poll_ns(GPollFD *fds, guint nfds, int64_t timeout)
{
#ifdef CONFIG_PPOLL
if (timeout < 0) {
return ppoll((struct pollfd *)fds, nfds, NULL, NULL);
} else {
struct timespec ts;
int64_t tvsec = timeout / 1000000000LL;
/* Avoid possibly overflowing and specifying a negative number of
* seconds, which would turn a very long timeout into a busy-wait.
*/
if (tvsec > (int64_t)INT32_MAX) {
tvsec = INT32_MAX;
}
ts.tv_sec = tvsec;
ts.tv_nsec = timeout % 1000000000LL;
return ppoll((struct pollfd *)fds, nfds, &ts, NULL);
}
#else
return g_poll(fds, nfds, qemu_timeout_ns_to_ms(timeout));
#endif
}如果 QEMU 配置了 PPOLL,qemu_poll_ns 函数会使用 PPOLL 实现 poll 探测,否则直接调用 g_poll 函数实现 poll 探测。
主事件循环
一般流程
QEMU 事件循环执行流程遵循 glib 标准,与普通应用的执行流程类似,相关函数的调用关系如下图所示:
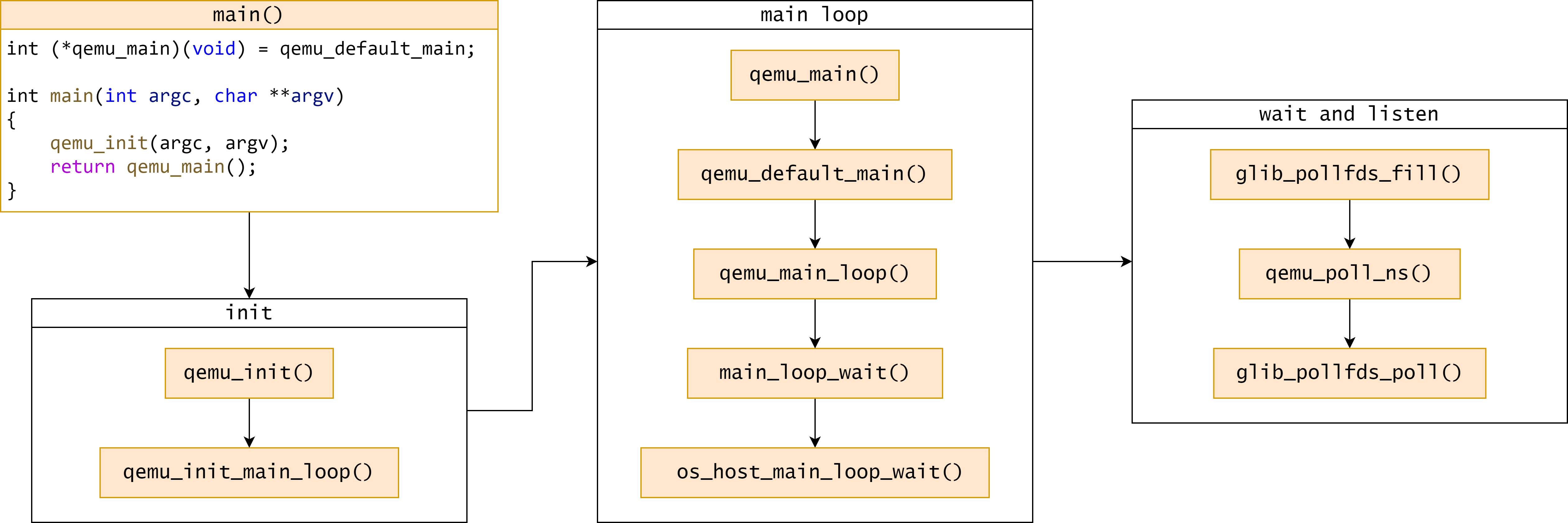
QEMU 的 main 函数定义在 softmmu/ vl.c 文件中,主函数在调用 qemu_init() 完成所有初始化工作之后会直接跳转函数 qemu_main 开始执行主事件循环。
初始化
QEMU 主事件循环初始化由 qemu_init_main_loop 函数负责:
/* util/main-loop.c: 156 */
int qemu_init_main_loop(Error **errp)
{
int ret;
GSource *src;
init_clocks(qemu_timer_notify_cb);
ret = qemu_signal_init(errp);
if (ret) {
return ret;
}
qemu_aio_context = aio_context_new(errp);
if (!qemu_aio_context) {
return -EMFILE;
}
qemu_set_current_aio_context(qemu_aio_context);
qemu_notify_bh = qemu_bh_new(notify_event_cb, NULL);
gpollfds = g_array_new(FALSE, FALSE, sizeof(GPollFD));
src = aio_get_g_source(qemu_aio_context);
g_source_set_name(src, "aio-context");
g_source_attach(src, NULL);
g_source_unref(src);
src = iohandler_get_g_source();
g_source_set_name(src, "io-handler");
g_source_attach(src, NULL);
g_source_unref(src);
return 0;
}观察上述代码可以发现,QEMU 事件初始化通过 glib 接口封装出本文开头所介绍的两种自定义事件源 qemu_aio_context 和 iohandler_ctx,然后将它们加入到 glib 默认的事件循环 default GMainContext 中。此外,一个上下文只在一个线程中运行,而 qemu_aio_context 和 iohandler_ctx 属于同一个上下文,因此可以运行在同一线程中。
关键函数
在上述函数调用关系图中,较为关键的是 os_host_main_loop_wait 函数,具体执行对 fd 的监听行为。需要注意的是,main_loop_wait 在调用 os_host_main_loop_wait 函数前,会调用 qemu_soonest_timeout 函数先计算一个最小的 timeout 值,该值是从定时器列表中获取的,表示监听事件的时候最多让主事件循环阻塞的时间,timeout 的存在使得 QEMU 能够及时处理系统中的定时器到期事件。
os_host_main_loop_wait 函数定义位于 util/main-loop.c 文件中,下面针对代码进行具体分析:
/* util/main-loop.c: 296 */
static int os_host_main_loop_wait(int64_t timeout)
{
GMainContext *context = g_main_context_default();
int ret;
g_main_context_acquire(context);
glib_pollfds_fill(&timeout);
qemu_mutex_unlock_iothread();
replay_mutex_unlock();
ret = qemu_poll_ns((GPollFD *)gpollfds->data, gpollfds->len, timeout);
replay_mutex_lock();
qemu_mutex_lock_iothread();
glib_pollfds_poll();
g_main_context_release(context);
return ret;
}在上述代码中,我们需要重点关注以下三个函数:
- glib_pollfds_fill: 检索事件源中待监控的 fd 集合
- qemu_poll_ns: QEMU 对
g_poll接口的封装实现,以纳秒为单位计算超时时间 - glib_pollfds_poll: 有事件发生,准备开始执行回调
其中 qemu_poll_ns 函数上文已经分析过,这里重点关注另外两个函数。
/* util/main-loop.c: 255 */
static void glib_pollfds_fill(int64_t *cur_timeout)
{
GMainContext *context = g_main_context_default();
int timeout = 0;
int64_t timeout_ns;
int n;
g_main_context_prepare(context, &max_priority);
glib_pollfds_idx = gpollfds->len;
n = glib_n_poll_fds;
do {
GPollFD *pfds;
glib_n_poll_fds = n;
g_array_set_size(gpollfds, glib_pollfds_idx + glib_n_poll_fds);
pfds = &g_array_index(gpollfds, GPollFD, glib_pollfds_idx);
n = g_main_context_query(context, max_priority, &timeout, pfds,
glib_n_poll_fds);
} while (n != glib_n_poll_fds);
if (timeout < 0) {
timeout_ns = -1;
} else {
timeout_ns = (int64_t)timeout * (int64_t)SCALE_MS;
}
*cur_timeout = qemu_soonest_timeout(timeout_ns, *cur_timeout);
}glib_pollfds_fill 函数的主要工作是获取所有需要进行监听的 fd,并且计算一个最小的超时时间。该函数首先调用 g_main_context_prepare 开始为主循环的监听做准备。接着在一个循环中调用 g_main_context_query 获取需要监听的 fd,所有 fd 保存在全局变量 gpollfds 数组中,需要监听的 fd 的数量保存在 glib_n_poll_fds 中,g_main_context_query 还会返回 fd 时间最小的 timeout,该值用来与传入的参数 cur_timeout 进行比较,选取较小值表示主循环的最大阻塞时间。
/* util/main-loop.c: 284 */
static void glib_pollfds_poll(void)
{
GMainContext *context = g_main_context_default();
GPollFD *pfds = &g_array_index(gpollfds, GPollFD, glib_pollfds_idx);
if (g_main_context_check(context, max_priority, pfds, glib_n_poll_fds)) {
g_main_context_dispatch(context);
}
}glib_pollfds_poll 函数负责对事件进行分发处理,它的代码结构比较简单,首先调用 glib 框架的 g_main_context_check 检测事件,然后再调用 g_main_context_dispatch 对事件进行分发处理。
事件处理
signalfd 是 Linux 的一个系统调用,可以将特定的信号与一个 fd 绑定,当有信号到达的时 fd 就会产生对应的可读事件。下面以 signalfd 为例梳理总结 QEMU 事件处理的过程。
初始化阶段主要逻辑如下:
- 调用
qemu_signal_init将一个 fd 与一组信号关联起来,qemu_signal_init调用qemu_set_fd_handler函数将该 signalfd 对应的可读回调函数设置为sigfd_handler qemu_set_fd_handler在首次调用时会调用iohandler_init创建一个全局的iohandler_ctx事件源,这个事件源的作用是监听 QEMU 中的各类事件qemu_signal_init在iohandlers_ctx的aio_handlers上挂载一个AioHandler节点,其 fd 为 signalfd,其io_read函数为sigfd_handler- 调用
aio_context_new创建一个全局的qemu_aio_context事件源,这个事件源主要用于处理 BH 和块设备层的同步使用 - 调用
aio_get_g_source和iohandler_get_g_source分别获取qemu_aio_context和iohandler_ctx的GSource成员变量,以该变量为参数调用g_source_attach两个AioContext加入主循环
将信号对应的 fd 加入事件源并将事件源加入主循环之后,QEMU 就会进入上文所述的 qemu_main_loop 函数循环进行事件监听。当使用 kill 命令向 QEMU 进程发送 SIGALARM 信号时,signalfd 就会有可读信号,从而导致主循环返回调用 g_main_context_dispatch 进行事件分发,这会调用 aio_ctx_dispatch,最终会调用 qemu_signal_init 注册的可读处理函数 sigfd_handler 进行事件处理。
总结
本文在 glib 事件循环机制的基础上,介绍了 QEMU 事件循环机制的基本组成,包括事件源、状态机回调函数以及 poll 机制,详细分析了 QEMU 主事件循环的运行原理,并以 signalfd 为例梳理了 QEMU 事件处理流程。在下一篇文章中,我们将继续深入分析 QEMU 下半部(Bottom Halvs,BH)机制。
参考资料
- 深入理解 QEMU 事件循环
- QEMU 事件循环机制
- QEMU Internals: Event loops
- 《QEMU/KVM 源码解析与应用》李强,机械工业出版社