QEMU 事件循环机制简析(三):下半部机制
前言
在上一篇文章中,我们详细分析了 QEMU 事件循环机制的基本组成,包括事件源、状态机回调函数以及 poll 机制,介绍了 QEMU 主事件循环的运行流程,本文将在此基础上进一步深入,以 8.0.0 版本的 QEMU RISC-V (qemu-system-riscv64) 为例,分析 QEMU 下半部(Bottom Halves,BH)机制。
在操作系统内核中,下半部是一个延迟执行的函数,在中断上下文之外运行。在 QEMU 中,下半部用于异步事件处理,QEMU 下半部机制利用事件循环机制,向其他模块提供异步调用的接口。因为其它模块的运行可能不在主线程中,但它想把自己注册的函数加入到 QEMU 主线程中运行,这时就可以使用下半部机制。QEMU 下半部功能在一个事件循环中实现,当下半部函数注册到一个事件循环中,这个事件循环在下一次 poll 的时候,就会调用该函数,从而实现异步延迟调用的效果。
数据结构
QEMU 将下半部机制所有必要信息(关联事件源、名称、回调函数和状态)进行抽象,封装为 QEMUBH 结构体:
/* util/async.c: 61 */
struct QEMUBH {
AioContext *ctx;
const char *name;
QEMUBHFunc *cb;
void *opaque;
QSLIST_ENTRY(QEMUBH) next;
unsigned flags;
};下面逐一分析该结构体各成员变量的含义与作用:
- AioContext *ctx: 指向
AioContext的指针,代表与下半部关联的异步 I/O 上下文。这允许 QEMU 在不同的上下文中处理不同的事件 - const char *name: 下半部名称
- QEMUBHFunc *cb: 指向回调函数的指针,当下半部被触发时,这个函数会被调用,这个回调函数通常会处理与下半部关联的事件
- void *opaque: 指向数据的指针,它可以在回调函数中使用,一般用于为回调函数提供参数或者额外的上下文数据。
- QSLIST_ENTRY(QEMUBH) next: 一个用于将
QEMUBH结构体插入到单向链表的宏 - unsigned flags: 用于存储底部半部的状态和属性的标志位,表示底部半部是否已经被调度或是否已经被删除
其中,flags 标志一共有五种:
/* util/async.c: 44 */
enum {
/* Already enqueued and waiting for aio_bh_poll() */
BH_PENDING = (1 << 0),
/* Invoke the callback */
BH_SCHEDULED = (1 << 1),
/* Delete without invoking callback */
BH_DELETED = (1 << 2),
/* Delete after invoking callback */
BH_ONESHOT = (1 << 3),
/* Schedule periodically when the event loop is idle */
BH_IDLE = (1 << 4),
};上述五种标志分别对应如下含义:
- BH_PENDING: 表示下半部已经入队并等待
aio_bh_poll()的处理,当一个下半部被调度但尚未执行时,设置为该状态 - BH_SCHEDULED: 表示下半部的回调函数应该被调用,当下半部被调度并准备执行其回调函数时,设置为该状态
- BH_DELETED: 表示下半部应该被删除,但在删除之前不应该调用其回调函数,这通常在下半部不再需要时使用以确保其回调函数不被执行
- BH_ONESHOT: 表示下半部应该在调用其回调函数后被删除,一般用于标示只需要执行一次的下半部
- BH_IDLE: 表示下半部应该在事件循环空闲时被周期性地调度,一般用于标示需要在没有其他活动时执行的任务很有用
为什么需要设置 flag 标志?因为 QEMU 下半部的注册和执行是异步的,因此需要有一种方法用来通知执行者下半部应该怎样执行。flag 标志的设置提供了一种方式来控制和管理下半部的行为。例如,可以组合使用这五种标志来确定是否应该执行下半部的回调函数,或者下半部是否应该在执行后被删除。
操作
挂载
QEMU 下半部在一个事件循环中实现,因此新建下半部需要指出基于哪个 AioContext,同时要指定下半部中需要执行什么函数以及函数参数,下半部的创建由 aio_bh_new_full 函数具体执行:
/* util/async.c: 139 */
QEMUBH *aio_bh_new_full(AioContext *ctx, QEMUBHFunc *cb, void *opaque,
const char *name)
{
QEMUBH *bh;
bh = g_new(QEMUBH, 1);
*bh = (QEMUBH){
.ctx = ctx,
.cb = cb,
.opaque = opaque,
.name = name,
};
return bh;
}下半部创建后需要挂载到相应 AioContext 的下半部列表中,该操作由 aio_bh_enqueue 完成:
/* util/async.c: 71 */
static void aio_bh_enqueue(QEMUBH *bh, unsigned new_flags)
{
AioContext *ctx = bh->ctx;
unsigned old_flags;
/*
* Synchronizes with atomic_fetch_and() in aio_bh_dequeue(), ensuring that
* insertion starts after BH_PENDING is set.
*/
old_flags = qatomic_fetch_or(&bh->flags, BH_PENDING | new_flags);
if (!(old_flags & BH_PENDING)) {
/*
* At this point the bottom half becomes visible to aio_bh_poll().
* This insertion thus synchronizes with QSLIST_MOVE_ATOMIC in
* aio_bh_poll(), ensuring that:
* 1. any writes needed by the callback are visible from the callback
* after aio_bh_dequeue() returns bh.
* 2. ctx is loaded before the callback has a chance to execute and bh
* could be freed.
*/
QSLIST_INSERT_HEAD_ATOMIC(&ctx->bh_list, bh, next);
}
aio_notify(ctx);
/*
* Workaround for record/replay.
* vCPU execution should be suspended when new BH is set.
* This is needed to avoid guest timeouts caused
* by the long cycles of the execution.
*/
icount_notify_exit();
}一个 AioContext 上可以有多个下半部挂载,下半部通过 AioContext 的 bh_list 成员以及自身数据结构中的 next 指针被维护成一个单向链表,如下图所示:
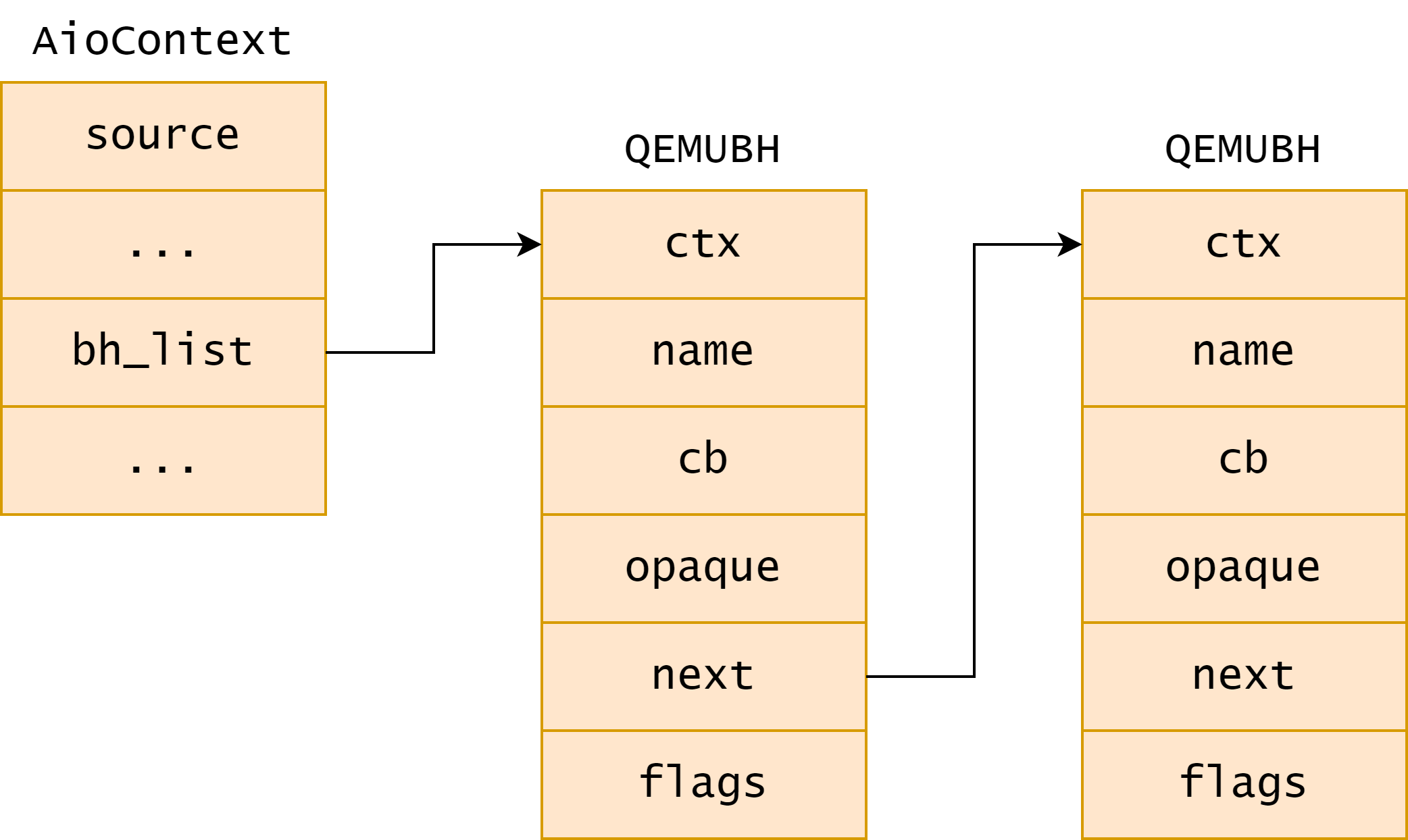
QEMU 主线程有默认的事件循环 qemu_aio_context,将下半部挂载到主线程的事件循环可以调用封装好的内部接口 qemu_bh_new:
/* include/qemu/main-loop.h: 390 */
#define qemu_bh_new(cb, opaque) \
qemu_bh_new_full((cb), (opaque), (stringify(cb)))一般 QEMU 下半部的执行方式是调用 qemu_bh_schedule 函数,将 flag 标志设置为 BH_SCHEDULED,即该下半部应该被计划执行:
/* util/async.c: 199 */
void qemu_bh_schedule(QEMUBH *bh)
{
aio_bh_enqueue(bh, BH_SCHEDULED);
}通过这种方式执行的下半部在执行一次以后不会被删除,因此下一次调度执行不需要重新注册。而通过 aio_bh_schedule_oneshot_full 接口创建并执行的下半部会在创建后尽快执行一次,然后就被删除:
/* util/async.c: 125 */
void aio_bh_schedule_oneshot_full(AioContext *ctx, QEMUBHFunc *cb,
void *opaque, const char *name)
{
QEMUBH *bh;
bh = g_new(QEMUBH, 1);
*bh = (QEMUBH){
.ctx = ctx,
.cb = cb,
.opaque = opaque,
.name = name,
};
aio_bh_enqueue(bh, BH_SCHEDULED | BH_ONESHOT);
}观察代码可以发现,aio_bh_schedule_oneshot_full 和 qemu_bh_schedule 函数主要有两处不同:aio_bh_schedule_oneshot_full 函数能够创建新的下半部,并且挂载时的 flag 标志比 qemu_bh_schedule 函数多一个 BH_ONESHOT。
通知
QEMU 下半部挂载到对应 AioContext 上并不会被立即执行,只有当事件循环的执行线程 poll 到 fd 准备好之后,才会触发回调执行下半部,如果对应 AioContext 的 fd 一直没有准备就绪,那么 poll 就一直不返回,挂载在上面的下半部就会一直得不到执行。为避免这类问题,QEMU 实现了下半部调度接口,用于通知事件循环调度下半部。
下半部调度接口通过 eventfd 实现,evenfd 可以用于线程间通信。QEMU 在 aio_context_new 创建 AioContext 时通过调用 event_notifier_init 函数初始化 EventNotifier,将 EventNotifier 中的 rfd 设置 aio_set_event_notifier 为事件循环要监听的 fd。当一个线程把自己的下半部挂载到 AioContext 上后,向 EventNotifier 中的 wfd 写入内容,另一端监听 rfd 的事件循环就会 poll 到其上有事件,然后触发下半部的调度:
/* util/async.c: 542 */
AioContext *aio_context_new(Error **errp)
{
int ret;
AioContext *ctx;
...
QSLIST_INIT(&ctx->bh_list);
...
ret = event_notifier_init(&ctx->notifier, false);
...
aio_set_event_notifier(ctx, &ctx->notifier,
false,
aio_context_notifier_cb,
aio_context_notifier_poll,
aio_context_notifier_poll_ready);
...
}执行
事件循环在 poll 到 fd 准备好之后,会调度 QEMU 定制的状态机回调函数 aio_ctx_dispatch,其主要功能是执行 fd 对应的回调函数,但在此之前会先检查 AioContext 上是否挂载有下半部,如果有则会先执行下半部。
aio_ctx_dispatch 和 aio_dispatch 函数在上一篇文章中已经详细分析过,本文不再赘述,这里我们重点关注具体落实下半部调度执行的函数 aio_bh_poll:
/* util/async.c: 159 */
int aio_bh_poll(AioContext *ctx)
{
BHListSlice slice;
BHListSlice *s;
int ret = 0;
/* Synchronizes with QSLIST_INSERT_HEAD_ATOMIC in aio_bh_enqueue(). */
QSLIST_MOVE_ATOMIC(&slice.bh_list, &ctx->bh_list);
QSIMPLEQ_INSERT_TAIL(&ctx->bh_slice_list, &slice, next);
while ((s = QSIMPLEQ_FIRST(&ctx->bh_slice_list))) {
QEMUBH *bh;
unsigned flags;
bh = aio_bh_dequeue(&s->bh_list, &flags);
if (!bh) {
QSIMPLEQ_REMOVE_HEAD(&ctx->bh_slice_list, next);
continue;
}
if ((flags & (BH_SCHEDULED | BH_DELETED)) == BH_SCHEDULED) {
/* Idle BHs don't count as progress */
if (!(flags & BH_IDLE)) {
ret = 1;
}
aio_bh_call(bh);
}
if (flags & (BH_DELETED | BH_ONESHOT)) {
g_free(bh);
}
}
return ret;
}aio_bh_poll 函数 QEMU 下半部机制的核心函数,这里首先定义了两个 BHListSlice 变量和一个返回值 ret。BHListSlice 是一个结构,它包含一个 BHList 类型的列表和一个后继指针 next。接着,函数两个宏将当前 AioContext 的 bh_list 列表中所有下半部移动到一个新的 BHListSlice 中,并将这个 BHListSlice 添加到 ctx->bh_slice_list 的尾部。这样做的目的是保证处理下半部时“先来先处理”的顺序,即新添加的下半部总是在最后得到处理。最后,函数使用 while 循环遍历 bh_slice_list 中所有的 BHListSlice,并更进一步地遍历 BHListSlice 中每一个下半部,对于计划执行并且没有被标记删除的下半部,函数会调度执行,对于一次性的或者是被标记删除的下半部,函数会删除它并释放资源。
在此过程中,有关数据结构的关系如下图所示:
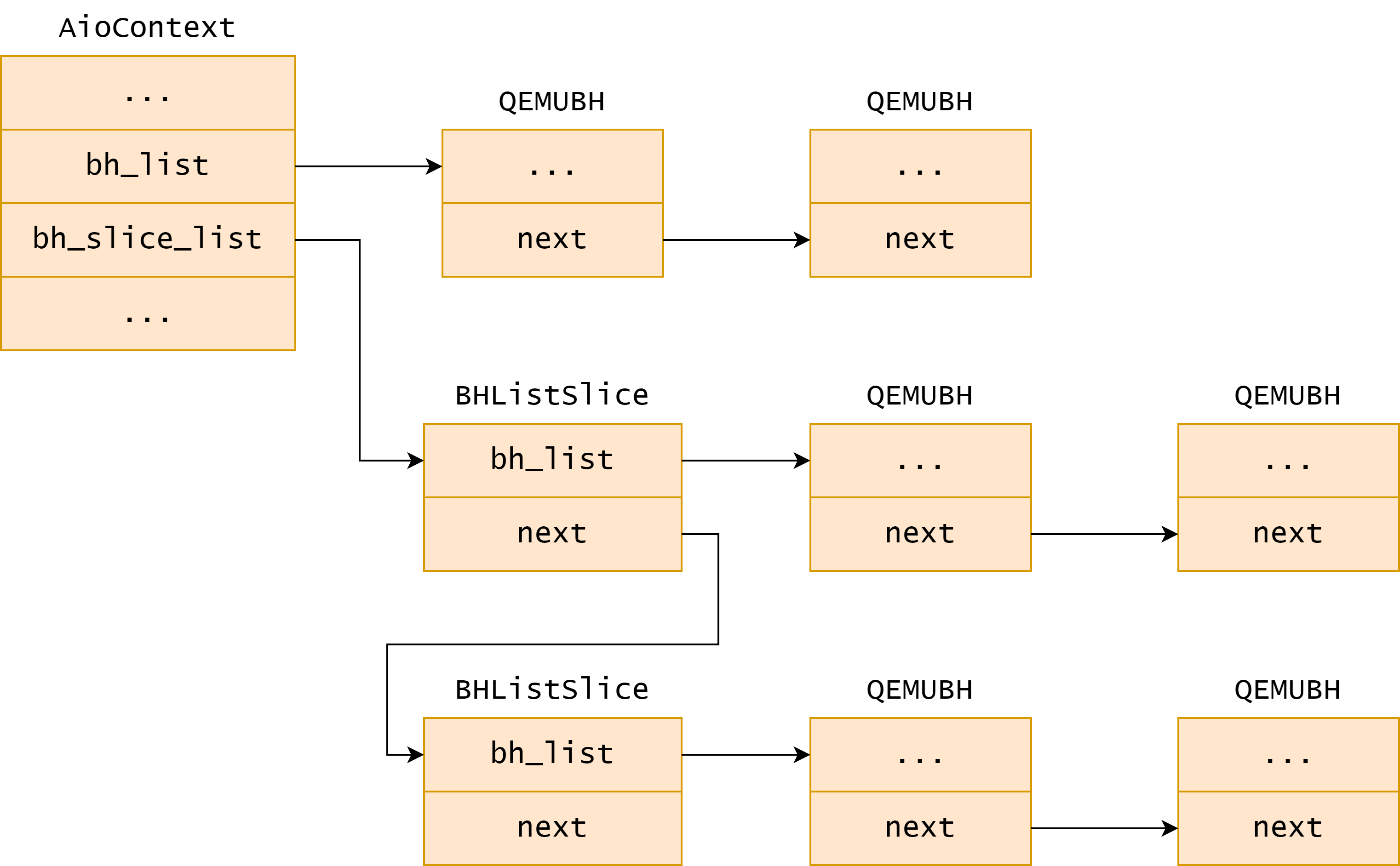
卸载
下半部卸载是通过调用 aio_bh_enqueue 函数更新 flag 标志完成的,设置 BH_DELETED 标志能够使下半部在下一次 dispatch 阶段被删掉并释放对应的内存空间:
/* util/async.c: 214 */
void qemu_bh_delete(QEMUBH *bh)
{
aio_bh_enqueue(bh, BH_DELETED);
}禁用
当我们希望下半部不再被事件循环调度,但又暂时不想删除这个下半部时可以调用 qemu_bh_cancel 函数实现:
/* util/async.c: 206 */
void qemu_bh_cancel(QEMUBH *bh)
{
qatomic_and(&bh->flags, ~BH_SCHEDULED);
}这个函数非常简洁,只有一行代码,使用原子操作来清除 bh->flags 中的 BH_SCHEDULED 标志。BH_SCHEDULED 标志表示这个下半部已经被计划执行,清除这个标志,意味着此后事件循环的 dispatch 时这个下半部不会再被调度执行。
总结
本文在前两篇文章的基础上,进一步分析了 QEMU 下半部机制,下半部利用事件循环机制,向其他模块提供异步调用的接口。文章梳理了下半部机制的主要数据结构以及它们之间的关系,介绍了 QEMU 下半部机制的执行原理,同时还整理了常见下半部操作的接口和用法。
参考资料
- 深入理解 QEMU 事件循环
- QEMU Internals: Event loops
- 《QEMU/KVM 源码解析与应用》李强,机械工业出版社